Once we are done with the initial Sanity checks with PD inputs, next step we move to the Floorplan .
It includes:
a. Die size estimation
b. IO placement
c. Macro Placement
d. Power routing
Floorplan is a critical and important step in PNR. A bad floor plan can cause all kind of issues related to timing, congestion, EM, IR, routing and noise.
Basic understanding of design, data-flow and module interactions is must to come up with a optimum floorplan.
Adding Physical cells, special cells , blockages and power mesh is part of flow. Placement of IO and macro is crucial and it needs thorough understanding and analysis.
for Top-down approach, we gets block size and shape from Top level. Where as in Bottom down, we need to come up with best block size based on instance count and other design requirements by our-self.
Die size consist of below important terms
• Core area = Standard cell area + memory area + macro area
• IO area = Total number of signal pads + total number of power pads
Design could become:
- Core limited : Where the number of pads determines the die size.
- Pad limited : Where the core logic determines the die size.
- Using both pad limited and core limited for a square die.
Important Formulas:
• Aspect Ratio = Height/Width
• Total Utilization = (Area of standard cells + macros + IO)/ Total area of die
FLOORPLAN CONTROLLING PARAMETERS:
1. Aspect Ratio = Horizontal routing resources/Vertical routing resources= H/V
A.R. =1, defines a square shape for the block
2. Utilization:
Core utilization: is the ratio of area occupied by standard cell, macros and blockages to the total core area. i.e.
Core utilization = (standard cell area+ macro cells area+blockages)/ total core area
A core utilization of 0.8 means that 80% of the area is available for placement of cells, whereas 20% is left free for routing.
STD Cell utilization: ratio of area occupied by std cells to the total core area and channel area.
Std cell utilization = std cell area/ (total cell area + channel area)
For Die Size Estimation
Technology Inputs:
Gate Density per sq. mm = D
Number of Horizontal Layers = H
Number of Vertical Layers = V
Design Inputs:
Gate count (excluding memories, macros & subchips) = G
IO area, in sq. mm = I
Memory + Macros + Subchips area, in sq.mm = M
Target Utilization, in percentage = U %
Additional gate count for CTS, timing closure etc, in percentage = T %
Additional gate count for ECOs, in percentage = E %
Die area calculation:
Die Area in sq.mm = {[(Gate count + Additional gate count for CTS & ECO) / Gate density] + IO area + Mem, Macro area} / Target utilization
Die Area = {[(G + T + E) / D] + I + M} / U
Aspect ratio, width, height calculation:
Aspect Ratio: AR = width / height
= Number of horizontal resources / Number of vertical resources
AR = H / V
Height : AR = W / H
W = H * AR ----- (1)
Area = W * H
= H * H * AR (Expressing W in terms of H from (1)
H2 = Area / AR
H = SQRT (Die Area / AR)
Width: W = H * AR
Correct I/O pad placement and selection is important for the correct function of any ASIC design.
- For a given ASIC design there are three types of I/O pads. These pads are power, ground, and signal.
- It is critical to functional operation of an ASIC design to insure that the pads have adequate power and ground connections and are placed properly in order to eliminate electromigration and current-switching noise related problems
BOND PADS
Pad placements are of two types.
▪Inline Bonding:
- All pads are of same height.
- Generally used in most of the designs.
- Can be used when design is not pad limited.
▪Staggered Bonding :
- Pads are of different heights.
- Can be used when design is pad limited.
- An area-bump bonded chip (or flip-chip), the chip is turned upside down and solder bumps connect the pads to the lead frame.
MACRO PLACEMENT
Manual macro placement is a preferred method for memory placement with the help of
- Fly-line analysis
- Data flow diagram
- Grouping (Macro Grouping, logic hierarchy)
Though we have Auto-placement option also available on tool .We can use it for initial memory placement when number of macros are huge and can refine it later.
By enabling Fly lines during macro placement, with the help of GUI, we can check and analyze how various modules/standard cells and IO's are communicating to each other.
Data flow diagram is provided by synthesis team, which helps in memory placement by providing an overview how data transfer is happening in design.
in GUI under hierarchy tab we can get all necessary information required to know before memory placement by highlighting different modules with different colors for different depths.
Guidelines to place the Macros :
- Place the macros around the core as much as possible.
- Do not place the macros in the middle of the core ,which would create congestion problem.
- Leave sufficient macros clearance for power routes and macro signal routes.
- Place the macros such that macros pins face towards the core area, in most of the cases the macro pins interact with standard cells.
- Place the macros close to IO pins, if it interacts with the specific IO's.
- Group the macros based on hierarchy and place all those close together.
- Check the fly line connection and place the the macros based on connectivity.
- Noise sensitive macros should be placed aside from noisy macro.
- Take a look at PORT COMMUNICATIONS.
- Avoid crisscross connectivity between macros.
- Leave a halo space between macros on all sides.
- For a non pin sides of macros a minimal separation is adequate.
- For pin sides of macros a larger separation is appropriate.
- Leave space between macro and the edge of chip/block, to allow for buffer insertion and power stripes to feed std cell rows between macros and blockages.
- Calculate distance between macros by:
[Number of pins * pitch/ Available metal layer] X [Margin(5-10%)]
Here available metal layers are, only effective routing layers. usually vertical layers after excluding M1,since it is dedicated for standard cells.
Guidelines for placing block-level pins:
- Determine the correct layer for the pins.
- Spread out the pins to reduce congestion.
- Avoid placing pins in corners where routing access is limited.
- Use multiple pin layers for less congestion.
- Never place cells within the perimeter of hard macros.
- To keep from blocking access to signal pins, avoid placing cells under power straps unless the straps are on metal layers higher than metal2.
- Use density constraints or placement-blockage arrays to reduce congestion.
- Avoid creating any blockage that increases congestion.
Qualifying floorplan:
- All macros should be placed and fixed.
- All IO pins must be placed and fixed.
- Block should have an uniform std cell area.
- Avoid notches.
- Legality check must pass.There should not be any overlaps between memories.
- Try to place memories across boundary areas until unless it is not an design requirement to place them in the center of the design. (only for exceptional cases like pvt sensor)
- Blockages must be applied properly around the memories to avoid un necessary congestion.
- There must be at least one VDD and VSS power strap between memories to avoid IR.
- Try to maintain free space in front of ports to have easy access for std cells talking.
- IO timing.
- Macro to macro timing.
- Macro to standard cell timing with margin.
- IR drop must be considered.
- Base DRC's should be clean(till m3) we consider base layers till M3 for DP violation(double pattern) ,since double pattering is used till M3.
Arriving at good floor plan takes multiple iterations, but its worth spending time to come up with a good floor plan. It will make further steps easy.
FLOORPLAN WITH POWER ISLANDS
- Static power consumption is determined by the foundry process.
- All CMOS processes leak whether the circuit is operating or not, so long as the circuit is powered on.
- To reduce this leakage we can vary the voltage, but varying it too much affects functional behavior.
- So the solution is by dividing the design into power islands and then turning off inactive islands will reduce leakage to zero.
- Dynamic power is the power required to produce work, whereas static power is the cost of having the power on. We derive dynamic power consumption using a simple equation: PD = CV2f
- A common technique for optimizing dynamic power is to employ hardware accelerators to perform functions that would have otherwise been a software-intensive, power-consuming load on the CPU.
- where C is the capacitance at the node, V is the voltage at which the node switches, and f is the switching frequency.
- Power Domain Partitioning
▪ More power regimes from PMIC(Power management integrated circuit , usually DC/AC converters or their control part.)
- Better Power Control and Efficiency
- Independent Voltage Scaling and Power Collapsing
- Increased PDN impedance and IR Drop
- Increased Bill Of Materials (BOM)
- Requires level shifters and resynchronization at boundaries.
- Need a small on-chip regulator with fast response and good efficiency
- IR Drop and PDN impedance
- Increased Power Density
- Increased metal resistance
- Increased IR due to Power Switches
- Dynamic IR affects on skew and timing not well modeled.
Level Shifter:
▪ Purpose of this cell is to shift the voltage from low to high as well as high to low. Generally buffer type and Latch type level shifters are available
High to Low Level Shifter:
Low to High Level Shifter:
▪ Isolation Cell:
- These are special cells required at the interface between blocks which are shut-down and always on. They clamp the output node to a known voltage. These cells needs to be placed in an ‘always on’ region only and the enable signal of the isolation cell needs to be ‘always_on’.
- In a nut-shell,an isolation cell is necessary to isolate floating inputs.
- Basic Isolation cell, Clamp to 0 and Clamp to 1.
- There are 2 types of isolation cells (a) Retain “0′′ (b) Retain “1
▪ Enable Level Shifter:
This cell is a combination of a Level Shifter and a Isolation cell.
▪ Retention Flops:
- These cells are special flops with multiple power supply. They are typically used as a shadow register to retain its value even if the block in which its residing is shut-down. All the paths leading to this register need to be ‘always_on’ and hence special care must be taken to synthesize/place/route them.
▪ AON cells:
- Generally these are buffers, that remains always powered irrespective of where they are placed.
- They can be either special cells or regular buffers. If special cells are used, they have their own secondary power supply and hence can be placed any where in the design. And when regular buffers are used they are placed such that they gets regular power supply. for e.g. placing them inside always on voltage island.
Voltage Island
Applying proper Blockages:
Blockage
guides the tool for the placement of different kind of cells in different regions of the design, based on the type of blockage.
Types:
Hard, Soft, Partial, Placement, Routing, Halos, Keep-Out regions
Hard
Blockage: is the kind of blockage which strictly don't allow
placement of any kind of standard-cell/buffer or inverter inside the hard blockage.
=>Usually
used in highly congested regions to prevent congestion.
=>
it will cause abrupt increase in the utilisation factor. So needs to make its use only on the critical basis or when we have enough margin.
Soft
Blockage: allows only buffers and inverters to get placed. It
does not impact total utilization of design.
Partial
Blockage: Based on the blockage factor, we can guide tool to
control the placement of standard cells for particular module in specific locations. It is a best method to control cell density Congestion. With
the help of blockage factor we can provide the percentage factor by which we want to control the std cell placement.
Placement
Blockage:
A
placement blockage is an area that cells must avoid during placement, optimization and legalization, including overlapping any part of the
placement blockage. A placement blockage can be hard or soft.
•A
hard blockage prevents cells from being placed in the blockage area.
•A
soft blockage restricts the coarse placer from putting cells in the blockage area, but optimization and legalization can place cells in a soft
blockage area.
If
you define both hard and soft placement blockages in a block, the hard placement blockages take priority over the soft placement blockages in
places where they overlap.
Routing
Blockage:
Routing
blockages blocks routing resources on one or more layers. It can be created at any point in the design. A routing blockage defines a region
where routing is not allowed on specific layers. Zroute considers routing blockages to be as hard constraints.
HALO
( Keep-Out Region):
HALO
is the region around the boundary of fixed macro in the design in which no other macro or std cells can be placed. Halo allows only the placement of
buffers and inverter s in its area.
Halos
of two adjacent macros can be overlapped.
If
the macros are moved from one place to another place, Halos will also get moved. But in the case of blockages if the macros are moved from one place
to another place the blockages cannot be moved.
Halo
does not add anything in total utilization whereas hard blockage usage cause abrupt increase in utilization factor.


















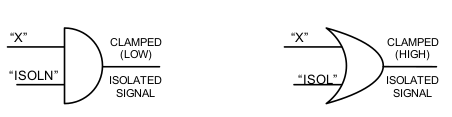



{kind=link}